Downloading software
Today's lab focuses the most common database language, the Strutured Query Language (SQL). While we can access a database using only Python commands, it is useful to see the results in a graphical interface. A simple implementation of SQL database is sqlitebrowser. You can download it from:
http://sqlitebrowser.org
After you download it, you should be able to launch it directly by clicking on the 3 stacked circles. If you get a warning on a Mac, click on it while holding down the Control Key, and then choose "Open" from the menu.
sqlite is accepts SQL queries and commands but does not support server access (i.e. remote access from other machines). If you need this, a popular (and also free) option is mysql.
A Simple Database
Many databases are "relational databases", meaning that the information is arranged around "relations" (tables) of data. This structure was introduced in 1970 by E.F. Codd at IBM, can be implemented very efficiently, and is very popular. Almost all relational databases can be accessed via the Structured Query Language (SQL).
Let's set up a simple database to demonstrate relations. Our first database will hold information about people and where they live.
- Open up sqlitebrowser (you may need to Ctrl-click and then choose Open from the menu).
- Click on "New Database" in the upper left hand corner.
- A dialog box will open and ask for a name for your database (I called mine cities).
- Another dialog box will open and ask for information for the table (relation) in your database:
- Fill in the top text box with a name for the table (i.e. inhabits).
- Next, click on the "Add Field" button to fields or attributes for the table. Let's first add a field "First Name" (doubleclick on Field1 to rename it) and make it type "TEXT" (use the pull down menu).
- Similarly, add in boxes for "Last Name" (TEXT), "Age" (INTEGER), "City" (TEXT),
"Population" (INTEGER), "Latitude" (REAL), "Longitude" (REAL).
- The bottom box shows the SQL commands that create the table in the database.
- Click on the OK button when you have entered all the fields.
Data Types
SQL has some built-in data types:
- INTEGER: whole numbers
- REAL: floating point or decimal numbers
- TEXT: strings (sequences of words)
- NULL: the undefined value
- BLOB: Binary Large Objects, used to store images and large text strings
When you create a column (attribute) for a table, you must specify what kind of data will be stored there.
Adding Data
Now, let's add some data to our table.
- Click on the "Browse Data" button (second row, middle).
- Click on the "New Record" button.
- A row will pop up with all NULL's (the default values).
- Let's fill in the top row with:
Barack Obama Washington DC 54 658,000 38.9072 -77.0369
- And another row:
Mike Bloomberg 74 New York City 8,406,000 40.7128 -74.0059
- And another row:
Ruth Bader Ginsburg 83 Washington DC 658,000 38.9072 -77.0369
- And another row:
Ellen Futter 66 New York City 8,406,000 40.7128 -74.0059
- And another row:
Sonia Sotomayor 61 Washington DC 658,000 38.9072 -77.0369
- And another row:
Lin-Manuel Miranda 36 New York City 8,406,000 40.7128 -74.0059
After you have entered in the names, click on "Write Changes" to save your entries.
Note: for larger amounts of data, there is an option to load in CSV files.
Challenges
- Add another resident of Washington DC to the table.
- Choose someone who lives in a different city and add them to the table.
Queries
Once information is stored in a database, SQL allows "queries" (formatted questions) that return data. The simplest queries are of the form:
SELECT * FROM inhabits;
To run this in sqlitebrowser, click "Execute SQL" from the second row of buttons. In the top text box, type the query above. When complete, click on the blue triangular run button (third row). In the lower box, you will see all elements ("*" is a wildcard that matches everything) from the table
inhabits.
If you are only interested in certain attributes, say just the last names and cities, you can select only those:
SELECT LastName, CityName FROM inhabits;
How would you just print out names and ages of the inhabitants?
You can also put conditions on which records (rows) you return, using the WHERE clause. For example, instead of printing out all inhabitants, let's print out the names of those under 70 years of age:
SELECT LastName, FirstName FROM inhabits WHERE age < 70;
SQL allows more complicated WHERE clauses. Almost all comparison operations as Python except SQL uses a single = for equality and < > for not equals.
Tables
So far, everything we've done so far can be done in Excel, so, why use a relational database? The answer comes in the use of tables to efficiently store information.
When we stored the information into our table inhabits, we ended up with much information duplicated. For example, the populations and coordinates for each city occur multiple times. If we needed to update the population of New York City, we would then need to do so in every single row for that city. To avoid such redundancy, information is split into smaller tables and linked where needed. For example, we could create a table with attributes:
Cities(CityName, Population, Latitude, Longitude)
to hold the city-specific information.
Another table could hold information about people:
People(FirstName, LastName, Age)
And our last table links the two together:
Inhabits(FirstName, LastName, CityName)
Now, the Inhabits table would have just 3 entries in each row (FirstName, LastName, City Name), and if we needed more information about the person or the city, we could look those up in the other two tables.
Let's create a new database to use three tables, instead of just one large one:
- Click on the "New Database" button, and name your new database "cities2".
- Since there will be multiple tables, let's use the Import option to load them in from CSV files (instead of typing the information in again).
We'll use people.csv, cities.csv, and inhabits.csv.
- Under the File menu, choose Import, and then "Table from CSV File".
Choose people.csv as your file and click Open.
- By default, the table will be named the same as the file. The attributes of the table are the column headers in the CSV vile.
Keys
We now have three tables that stored the information of the first one.
This avoids the repetition of storing data (e.g. the latitude, longitude, and population) in the entry for every person. Instead, we stored just enough information (in this case, the city's name) to be able to look up the additional data about a city, if needed. Similarly, the inhabits table keeps just enough information (e.g. first and last names) to be able to locate the additional information about people. An attribute that uniquely identifies a row in the table is called a key. We can specify a key in sqlitebrowser by clicking the "PK" option when adding fields to the table (which is equivalent to the SQL command "PRIMARY KEY( fieldName )").
Databases are often presented as the table names and attributes. Our small database has the database schema:
cities(CityName, Population, Latitude, Longitude)
inhabits(FirstName, LastName, CityName)
people(FirstName, LastName, Age)
A simple way to link data across multiple tables is using the WHERE clause.
In the clause, we align rows of the tables by common attributes. For example:
select Age, CityName from people, inhabits
where people.FirstName = inhabits.FirstName;
Above, since the same attribute name occurs in multiple tables, we specify which table to by using the table name as a prefix (e.g. people.FirstName).
What happens if you leave off the where clause? Why?
Challenges
- Modify the cities table to store city populations rounded to the nearest 10,000 (currently rounds to nearest 1,000).
- Write a query that prints out the names of all over 60 years old.
- Write a query that prints out the names of all over 60 years old who also reside in Washington DC.
Entity/Relationship (E/R) Diagrams
Entity/Relationship (E/R) diagrams are often used to represent visually the organization of the database. The notation is:
- Boxes: entities
- Circles: attributes
- Diamonds: relationships
- Underlining: Keys
Here is an E/R diagram from Stanford's InfoLab representing episodes of a televion series.
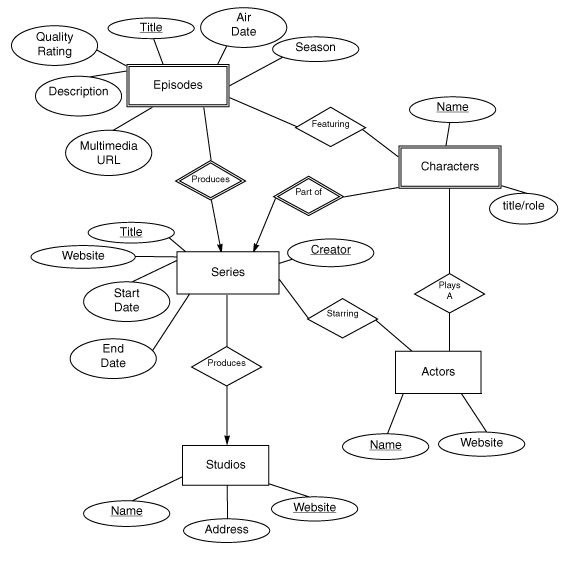
Note that each box corresponds to a table (Episodes, Series, etc). When implementing this in a database all the diamonds (relationships) are also implemented by tables, much as we did with the inhabits table in our simple database above.
And a more complicated one for fossils. It is machine generated by the database management system used and represents tables by boxes and includes attributes inside each box:
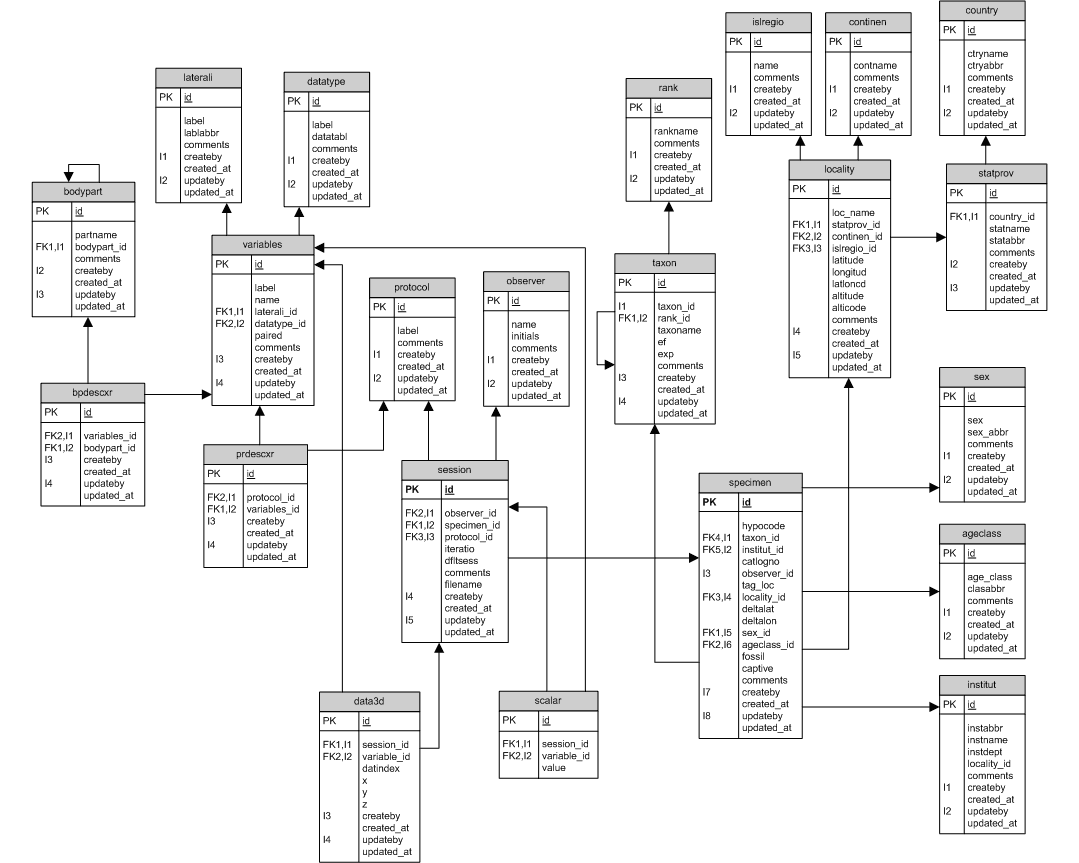
Challenges:
- Draw the E/R diagram for our inhabitants database with its 3 tables.
- Draw an E/R diagram for the CSV file from Lab 5. Group similar information together to avoid storing data (other than keys) in multiple locations.
- Translate your E/R diagram into a database schema (a list of the tables and their attributes).
- (Optional): Break your CSV file (using Python or Excel) into files that correspond to the tables in the database you designed above and use those to populate your database.