Program 2: Parking Tickets
CSci 39542: Introduction to Data Science
Department of Computer Science
Hunter College, City University of New York
Spring 2022
Classwork Quizzes Homework Project
Program Description
Program 2: Parking Tickets. Due noon, Thursday, 17 February.
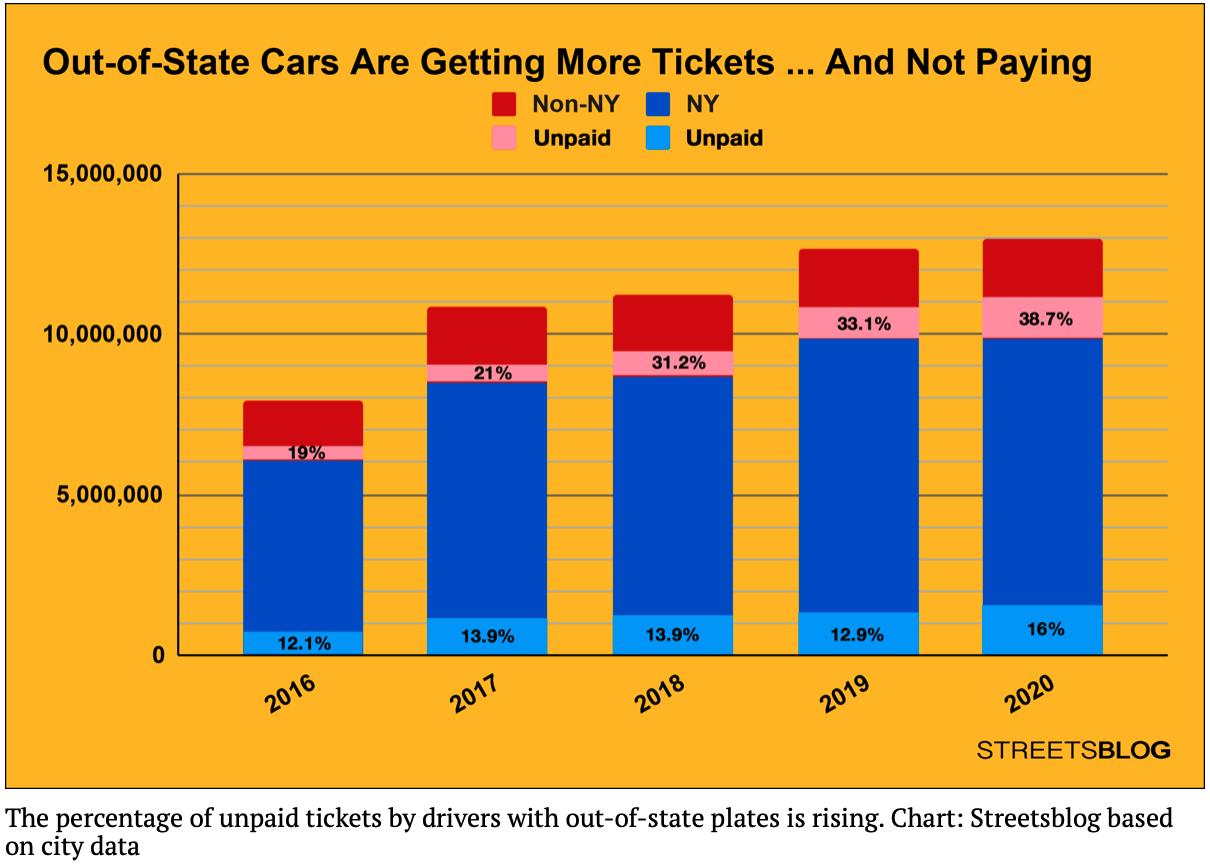
Recent news articles focused on the significantly higher percentage of parking tickets that are unpaid for cars with out-of-state plates:
The data is aggregated across the whole city. Does the same occur when the datasets are focused on individual neighborhoods? To answer that question, as well as what are the most common reasons for tickets, we will use the parking ticket data from OpenData NYC. In Lecture 3, we started data cleaning efforts on the parking ticket data. We will continue the data cleaning efforts for this program, as well as introduce auxiliary files that link the codes stored with a short explanation of the violation. The assignment is broken into the following functions to allow for unit testing:
For example, assuming your functions are in the Looking at the registration types ( And for the Precinct District 19 dataset that contains almost a half million tickets:
Learning Objective: to refresh students' knowledge of Pandas' functionality to manipulate and create columns from formatted data.
Available Libraries: Pandas and core Python 3.6+.
Data Sources: Parking Tickets, NYC OpenData
and Parking ticket violation codes (summary of codes & fines).
Sample Datasets:
make_df(file_name):
This function takes one input:
The function should open the file file_name: the name of a CSV file containing Parking Ticket Data from OpenData NYC.
file_name as DataFrame, drop all but the columns:
and return the resulting DataFrame.
Summons Number,Plate ID,Registration State,Plate Type,Issue Date,Violation Code,Violation Time,
Violation In Front Of Or Opposite,House Number,Street Name,Vehicle Color
filter_reg(df, keep = ["COM", "PAS"]):
This function takes two inputs:
The function returns the DataFrame with only rows that have df: a DataFrame that
including the Plate Type column.
keep: a list of values for the
Plate Type column.
The default value is ["COM", "PAS"].
Plate Type with a value from the list keep. All rows where the Plate Type column contains a different value are dropped.
add_indicator(reg_state):
This function takes one input:
The function should return reg_state: a string containing the state of registation.
1 when reg_state is in ["NY","NJ","CT"] and 0 otherwise.
find_tickets(df, plate_id):
This function takes two inputs:
returns, as a list, the df: a DataFrame that
including the Plate ID column.
plate_id: a string containing a license plate (combination of letters, numbers and spaces).
Violation Code for all tickets issued to that plate_id. If that plate_id has no tickets in the DataFrame, then an empty list is returned.
make_dict(file_name, skip_rows = 1):
This function takes two inputs:
Make a dictionary from a text file named file_name: a string containing the name of a file.
skip_rows: the number of rows to skip at the beginning of file.
The default value is 1.
file_name, where each line, after those that are skipped, makes a dictionary entry. The key for each entry is the string upto the first comma (',') and the value is the string between the first and second commas. All characters after the second comma on a line are ignored.
p2.py:
will print:
df = p2.make_df('Parking_Violations_Issued_Precinct_19_2021.csv')
print(df)
Note that all the rows are included (451,509) but that only the 11 specified columns are retained in the DataFrame.
Summons Number Plate ID ... Street Name Vehicle Color
0 1474094223 KDT3875 ... E 75 BLACK
1 1474094600 GTW5034 ... EAST 70 STREET BK
2 1474116280 HXM6089 ... E 72 ST BK
3 1474116310 HRW4832 ... E 72 ST GRY
4 1474143209 JPR6583 ... EAST 94 STREET BLACK
... ... ... ... ... ...
451504 8954357854 JRF3892 ... 5th Ave GR
451505 8955665040 199VP4 ... E 74th St BLACK
451506 8955665064 196WL7 ... E 78th St BLACK
451507 8970451729 CNK4113 ... York Ave GY
451508 8998400418 XJWV98 ... York Ave WHITE
[451509 rows x 11 columns]Plate Type):
prints many different types of registrations and abbreviations:
print(f"Registration: {df['Plate Type'].unique()}")
print(f"\n10 Most Common: {df['Plate Type'].value_counts()[:10]}")
The two registration types that are the most common:
Registration: ['PAS' 'SRF' 'OMS' 'COM' '999' 'SPO' 'OMT' 'MOT' 'RGL' 'PHS' 'MED' 'TRC'
'APP' 'SRN' 'OML' 'ITP' 'CMB' 'ORG' 'AMB' 'DLR' 'IRP' 'TOW' 'MCL' 'CBS'
'LMB' 'USC' 'CME' 'RGC' 'VAS' 'ORC' 'HIS' 'STG' 'AGR' 'TRA' 'CHC' 'SOS'
'BOB' 'OMR' 'TRL' 'AGC' 'CSP' 'PSD' 'SPC' 'MCD' 'NLM' 'CMH' 'LMA' 'JCA'
'SCL' 'HAM' 'AYG' 'NYA' 'OMV']
10 Most Common: PAS 262875
COM 168827
SRF 2834
APP 2800
OMT 2603
OMS 2464
MED 1433
999 1352
CMB 1208
LMB 1135
Name: Plate Type, dtype: int64count = len(df)
pasCount = len(df[df['Plate Type'] == 'PAS'])
comCount = len(df[df['Plate Type'] == 'COM'])
print(f'{count} different vehicles, {100*(pasCount+comCount)/count} percent are passenger or commercial plates.')
Our function will filter for just passenger and commercial plates:
451509 different vehicles, 95.61315499801776 percent are passenger or commercial plates.
will print:
dff = p2.filter_reg(df)
print(f'The length of the filtered data frame is {len(dff)}.')
By specifying different registration types with the keyword argument, we can filter for other registration (DMV's Registration Types) such as motocycles:
The length of the filtered data frame is 431702.
df2 = p2.filter_reg(df,keep=['MOT','HSM','LMA','LMB'])
print(f'The length of the filtered data frame is {len(df2)}.')The length of the filtered data frame is 2095.df2['NYPlates'] = df2['Registration State'].apply(p2.add_indicator)
print(df2.head()) Summons Number Plate ID ... Vehicle Color NYPlates
3888 8778381423 MD677M ... SILVE 1
5967 1475041184 92BF34 ... BLK 1
6177 1477342850 40TZ78 ... RD 1
6985 8514394770 16UD95 ... BLACK 1
7221 8624098440 77BD79 ... BLACK 1Plate ID and use the dictionary of the violation code to find out what the tickets were for:
print(f'Motorcycles with most tickets:\n {df2["Plate ID"].value_counts()[:5]}')
code_lookup = p2.make_dict('ticket_codes.csv')
ticket_codes = p2.find_tickets(df2,'19UB23')
descrip = [code_lookup[str(t)] for t in ticket_codes]
print(f'The motocycle with plate 19UB23 got the following tickets: {descrip}')Motorcycles with most tickets:
19UB23 14
80BD05 10
38SV33 9
66TZ74 8
70TW50 8
Name: Plate ID, dtype: int64
The motocycle with plate 19UB23 got the following tickets: ['NO PARKING-STREET CLEANING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'INSP. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'INSP. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING', 'REG. STICKER-EXPIRED/MISSING']Note: you should submit a file with only the standard comments at the top, this function, and any helper functions you have written. The grading scripts will then import the file for testing. If your file includes code outside of functions, either comment the code out before submitting or use a main function that is conditionally executed (see Think CS: Section 6.8 for details).
Hints:- Parking ticket data can be found at: NYC OpenData.
- Some datasets for testing:
- parking_test_100.csv: A truncated file for testing-- first 100 rows of the 2021 UES parking tickets (described below).
- Parking_Violations_Issued_Precinct_19_2021.csv: ~450,000 line file of parking violations issues in 2021 for the Upper East Side (District 19)
- Parking ticket violation codes (summary of codes & fines) are the basis for the dictionary.
- ticket_codes.csv from OpenData NYC.
- You may get a warning such as:
sys:1: DtypeWarning: Columns (39) have mixed types.Specify dtype option on import or set low_memory=False.when reading in the parking ticket data. Pandas tries to infer the data type (dtype) of the columns from the values. Since some columns are a mixture of numeric and character types this can be difficult. If the file is read in withpd.read_csv(file_name, low_memory=False), the entire column is read in and used to determine type.